



What are Large Language Models (LLMs)?
They are Intelligent Text Generators: At their core, LLMs are advanced computer programs that can generate, understand, and manipulate human language with remarkable fluency and coherence. Think of them as supercharged autocomplete systems on steroids!
They are trained on Massive Data: LLMs are trained on enormous amounts of text data, including books, articles, code, and any other possible forms of written communication. This allows them to learn the human language's intricate patterns, grammar rules, and even nuances.
GPT-3 (OpenAI): A landmark LLM with 175 billion parameters. It became famous for its ability to generate human-quality text and perform various language tasks.
GPT-4 (OpenAI): The latest iteration from OpenAI, GPT-4 extends LLM capabilities even further. According to information gathered, there are conflicting reports on the exact number of parameters in GPT-4. The estimates range from 220 billion parameters to 1.76 trillion parameters. The most common estimates suggest that GPT-4 has around 1.7 trillion parameters. GPT-4 demonstrates advancements in reasoning, multi-modal input processing (text and images), and improved safety and alignment with human values.
Megatron-Turing NLG (NVIDIA and Microsoft): A powerhouse with 530 billion parameters, known for its strengths in natural language generation and understanding.
Jurassic-1 Jumbo (AI21 Labs): This LLM consists of 178 billion parameters and is designed for factual language generation.
WuDao 2.0 (BAAI): One of the largest LLMs to date, featuring a staggering 1.75 trillion parameters.
PaLM (Google AI): An LLM with 540 billion parameters, showcasing impressive performance on reasoning tasks and code generation.
LLaMA (Meta AI): A recent release featuring LLMs ranging from 7 billion to 65 billion parameters. Notably, LLaMA models are available to researchers under a non-commercial license.
GLaM (Google AI): With 137 billion parameters, GLaM (Generalist Language Model) offers exceptional few-shot learning abilities. It uses a sparsely activated mixture-of-experts architecture.
The AI space is very open source today, so there are many more LLMs being released on platforms like Huggingface everyday.
Prediction Power: Their primary function is to predict the next word or sequence of words given a piece of text as input. As they're trained on vast datasets, they gain a remarkable ability to generate text that's often indistinguishable from human-written text.
How Do LLMs Work?
Transformer Architecture: Most LLMs are built upon a powerful neural network architecture called the Transformer. This architecture uses a clever mechanism called "attention" to weigh the importance of different words within a sentence, helping the model understand the context. The transformer network was an innovation that came in the paper by Vaswani et. al., in their paper "Attention is all you need".
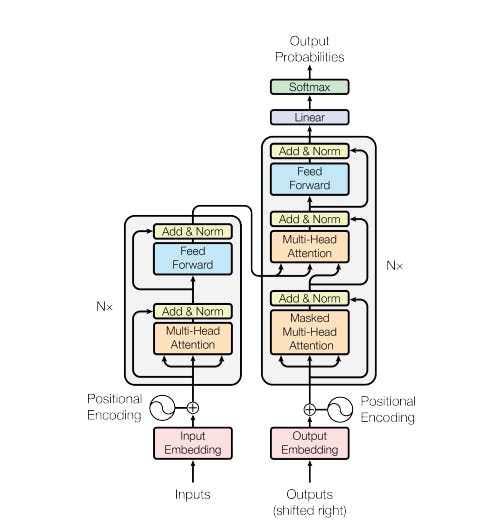
Scaling Up: A key principle of LLMs is scale. The more data they're trained on, and the more parameters (adjustable variables) they have in their models, the better they become at generating realistic and contextually appropriate text.
Pre-training and Fine-Tuning: LLMs often undergo two phases of training:
Pre-training: Initial training on a massive, general dataset to learn basic language patterns.
Fine-tuning: Further training on task-specific data to optimize for tasks like translation, question-answering, or creative writing.
Key Abilities of LLMs
Text Generation: LLMs can write different kinds of creative text formats, like poems, code, scripts, musical pieces, and email.
Translation: They can translate languages with impressive accuracy and fluency.
Summarization: They can create summaries of factual topics or complex articles.
Question-Answering: LLMs can process open-ended questions and generate informative answers based on their vast knowledge acquired during training.
And Many More: New abilities are constantly emerging as scientists push the boundaries of LLM capabilities.
As LLMs grow, they exhibit remarkable capabilities beyond their original training objectives. These "emergent abilities" are not explicitly trained but they manifest spontaneously as the model's size increases. From performing arithmetic to answering questions and summarizing passages, these new skills seem to emerge organically, hence the term "emergent." It's as if the models unlock novel proficiencies simply by scaling up, revealing the profound potential of massive language models to develop unforeseen talents.
Challenges and Considerations
Hallucinations: LLMs sometimes generate nonsensical or incorrect text because they prioritize producing plausible-sounding text over absolute truthfulness.
Bias: LLMs can reflect biases in their training data, leading to potential harm. Developing techniques to mitigate these biases is crucial.
The Future of LLMs
LLMs hold immense potential to revolutionize how we interact with computers and create new forms of creative expression. As research progresses, we can expect LLMs to become even more powerful, versatile, and aligned with human values, unlocking new possibilities across industries and everyday life.